Анализ бинарного кода, то есть кода, который выполняется непосредственно машиной, – нетривиальная задача. В большинстве случаев, если надо проанализировать бинарный код, его восстанавливают сначала посредством дизассемблирования, а потом декомпиляции в некоторое высокоуровневое представление, а дальше уже анализируют то, что получилось.
Здесь надо сказать, что код, который восстановили, по текстовому представлению имеет мало общего с тем кодом, который был изначально написан программистом и скомпилирован в исполняемый файл. Восстановить точно бинарный файл, полученный от компилируемых языков программирования типа C/C++, Fortran, нельзя, так как это алгоритмически неформализованная задача. В процессе преобразования исходного кода, который написал программист, в программу, которую выполняет машина, компилятор выполняет необратимые преобразования.
В 90-е годы прошлого века было распространено суждение о том, что компилятор как мясорубка перемалывает исходную программу, и задача восстановить ее схожа с задачей восстановления барана из сосиски.
Однако не так все плохо. В процессе получения сосиски баран утрачивает свою функциональность, тогда как бинарная программа ее сохраняет. Если бы полученная в результате сосиска могла бегать и прыгать, то задачи были бы схожие.
Итак, раз бинарная программа сохранила свою функциональность, можно говорить, что есть возможность восстановить исполняемый код в высокоуровневое представление так, чтобы функциональность бинарной программы, исходного представления которой нет, и программы, текстовое представление которой мы получили, были эквивалентными.
По определению две программы функционально эквивалентны, если на одних и тех же входных данных обе завершают или не завершают свое выполнение и, если выполнение завершается, выдают одинаковый результат.
Задача дизассемблирования обычно решается в полуавтоматическом режиме, то есть специалист делает восстановление вручную при помощи интерактивных инструментов, например, интерактивным дизассемблером IdaPro , radare или другим инструментом. Дальше также в полуавтоматическом режиме выполняется декомпиляция. В качестве инструментального средства декомпиляции в помощь специалисту используют HexRays , SmartDecompiler или другой декомпилятор, который подходит для решения данной задачи декомпиляции.
Восстановление исходного текстового представления программы из byte-кода можно сделать достаточно точным. Для интерпретируемых языков типа Java или языков семейства.NET, трансляция которых выполняется в byte-код, задача декомпиляции решается по-другому. Этот вопрос мы в данной статье не рассматриваем.
Итак, анализировать бинарные программы можно посредством декомпиляции. Обычно такой анализ выполняют, чтобы разобраться в поведении программы с целью ее замены или модификации.
Из практики работы с унаследованными программами
Некоторое программное обеспечение, написанное 40 лет назад на семействе низкоуровневых языков С и Fortran, управляет оборудованием по добыче нефти. Сбой этого оборудования может быть критичным для производства, поэтому менять ПО крайне нежелательно. Однако за давностью лет исходные коды были утрачены.Новый сотрудник отдела информационной безопасности, в обязанности которого входило понимать, как что работает, обнаружил, что программа контроля датчиков с некоторой регулярностью что-то пишет на диск, а что пишет и как эту информацию можно использовать, непонятно. Также у него возникла идея, что мониторинг работы оборудования можно вывести на один большой экран. Для этого надо было разобраться, как работает программа, что и в каком формате она пишет на диск, как эту информацию можно интерпретировать.
Для решения задачи была применена технология декомпиляции с последующим анализом восстановленного кода. Мы сначала дизассемблировали программные компоненты по одному, дальше сделали локализацию кода, который отвечал за ввод-вывод информации, и стали постепенно от этого кода выполнять восстановление, учитывая зависимости. Затем была восстановлена логика работы программы, что позволило ответить на все вопросы службы безопасности относительно анализируемого программного обеспечения.
Если требуется анализ бинарной программы с целью восстановления логики ее работы, частичного или полного восстановления логики преобразования входных данных в выходные и т.д., удобно делать это с помощью декомпилятора.
Помимо таких задач, на практике встречаются задачи анализа бинарных программ по требованиям информационной безопасности. При этом у заказчика не всегда есть понимание, что этот анализ очень трудоемкий. Казалось бы, сделай декомпиляцию и прогони получившийся код статическим анализатором. Но в результате качественного анализа практически никогда не получится.
Во-первых, найденные уязвимости надо уметь не только находить, но и объяснять. Если уязвимость была найдена в программе на языке высокого уровня, аналитик или инструментальное средство анализа кода показывают в ней, какие фрагменты кода содержат те или иные недостатки, наличие которых стало причиной появления уязвимости. Что делать, если исходного кода нет? Как показать, какой код стал причиной появления уязвимости?
Декомпилятор восстанавливает код, который «замусорен» артефактами восстановления, и делать отображение выявленной уязвимости на такой код бесполезно, все равно ничего не понятно. Более того, восстановленный код плохо структурирован и поэтому плохо поддается инструментальным средствам анализа кода. Объяснять уязвимость в терминах бинарной программы тоже сложно, ведь тот, для кого делается объяснение, должен хорошо разбираться в бинарном представлении программ.
Во-вторых, бинарный анализ по требованиям ИБ надо проводить с пониманием, что делать с получившимся результатом, так как поправить уязвимость в бинарном коде очень сложно, а исходного кода нет.
Несмотря на все особенности и сложности проведения статического анализа бинарных программ по требованиям ИБ, ситуаций, когда такой анализ выполнять нужно, много. Если исходного кода по каким-то причинам нет, а бинарная программа выполняет функционал, критичный по требованиям ИБ, ее надо проверять. Если уязвимости обнаружены, такое приложение надо оправлять на доработку, если это возможно, либо делать для него дополнительную «оболочку», которая позволит контролировать движение чувствительной информации.
Когда уязвимость спряталась в бинарном файле
Если код, который выполняет программа, имеет высокий уровень критичности, даже при наличии исходного текста программы на языке высокого уровня, полезно сделать аудит бинарного файла. Это поможет исключить особенности, которые может привнести компилятор, выполняя оптимизирующие преобразования. Так, в сентябре 2017 года широко обсуждали оптимизационное преобразование, выполненное компилятором Clang. Его результатом стал вызов функции , которая никогда не должна вызываться. #include
В результате оптимизационных преобразований компилятором будет получен вот такой ассемблерный код. Пример был скомпилирован под ОС Linux X86 c флагом -O2.
Text .globl NeverCalled .align 16, 0x90 .type NeverCalled,@function NeverCalled: # @NeverCalled retl .Lfunc_end0: .size NeverCalled, .Lfunc_end0-NeverCalled .globl main .align 16, 0x90 .type main,@function main: # @main subl $12, %esp movl $.L.str, (%esp) calll system addl $12, %esp retl .Lfunc_end1: .size main, .Lfunc_end1-main .type .L.str,@object # @.str .section .rodata.str1.1,"aMS",@progbits,1 .L.str: .asciz "rm -rf /" .size .L.str, 9
В исходном коде есть undefined behavior . Функция NeverCalled() вызывается из-за оптимизационных преобразований, которые выполняет компилятор. В процессе оптимизации он скорее всего выполняет анализ аллиасов , и в результате функция Do() получает адрес функции NeverCalled(). А так как в методе main() вызывается функция Do(), которая не определена, что и есть неопределенное стандартом поведение (undefined behavior), получается такой результат: вызывается функция EraseAll(), которая выполняет команду «rm -rf /».
Следующий пример: в результате оптимизационных преобразований компилятора мы лишились проверки указателя на NULL перед его разыменованием.
#include
Так как в строке 3 выполняется разыменование указателя, компилятор предполагает, что указатель ненулевой. Дальше строка 4 была удалена в результате выполнения оптимизации «удаление недостижимого кода» , так как сравнение считается избыточным, а после и строка 3 была удалена компилятором в результате оптимизации «удаление мертвого кода» (dead code elimination). Остается только строка 5. Ассемблерный код, полученный в результате компиляции gcc 7.3 под ОС Linux x86 с флагом -O2, приведен ниже.
Text .p2align 4,15 .globl _Z7CheckerPi .type _Z7CheckerPi, @function _Z7CheckerPi: movl 4(%esp), %eax movl $8, (%eax) ret
Приведенные выше примеры работы оптимизации компилятора – результат наличия в коде undefined behavior UB. Однако это вполне нормальный код, который большинство программистов примут за безопасный. Сегодня программисты уделяют время исключению неопределенного поведения в программе, тогда как еще 10 лет назад не обращали на это внимания. В результате унаследованный код может содержать уязвимости, связанные с наличием UB.
Большинство современных статических анализаторов исходного кода не обнаруживают ошибки, связанные с UB. Следовательно, если код выполняет критичный по требованиям информационной безопасности функционал, надо проверять и его исходники, и непосредственно тот код, который будет выполняться.
В связи с растущим объемом разрабатываемого ПО проблема безопасности становится все более актуальной. Одним из вариантов ее решения может стать применение безопасного цикла создания продуктов, включая планирование, проектирование, разработку, тестирование. Такой подход позволяет получать на выходе решение с продуманной системой безопасности, которое не потребуется затем многократно “латать" из-за существующих уязвимостей. В данной статье пойдет речь об одной из важных практик, применяемых на этапе тестирования, – статическом анализе кода.
Александр Миноженко
Старший исследователь департамента анализа кода
в ERPScan (дочерняя компания Digital Security)
При статическом анализе кода происходит анализ программы без ее реального исполнения, а при динамическом анализе – в процессе исполнения. В большинстве случаев под статическим анализом подразумевают анализ, осуществляемый с помощью автоматизированных инструментов исходного или исполняемого кода.
Исторически первые инструменты статического анализа (часто в их названии используется слово lint) применялись для нахождения простейших дефектов программы. Они использовали простой поиск по сигнатурам, то есть обнаруживали совпадения с имеющимися сигнатурами в базе проверок. Они применяются до сих пор и позволяют определять "подозрительные" конструкции в коде, которые могут вызвать падение программы при выполнении.
Недостатков у такого метода немало. Основным является то, что множество "подозрительных" конструкций в коде не всегда являются дефектами. В большинстве случаев такой код может быть синтаксически правильным и работать корректно. Соотношение "шума" к реальным дефектам может достигать 100:1 на больших проектах. Таким образом, разработчику приходится тратить много времени на его отсеивание от реальных дефектов, что отменяет плюсы автоматизированного поиска.
Несмотря на очевидные недостатки, такие простые утилиты для поиска уязвимостей до сих пор используются. Обычно они распространяются бесплатно, так как коммерческого применения они, по понятным причинам, не получили.
Второе поколение инструментов статического анализа в дополнение к простому поиску совпадений по шаблонам оснащено технологиями анализа, которые до этого применялись в компиляторах для оптимизации программ. Эти методы позволяли по анализу исходного кода составлять графы потока управления и потока данных, которые представляют собой модель выполнения программы и модель зависимостей одних переменных от других. Имея данные, графы можно моделировать, определяя, как будет выполняться программа (по какому пути и с какими данными).
Поскольку программа состоит из множества функций, процедур модулей, которые могут зависеть друг от друга, недостаточно анализировать каждый файл по отдельности. Для полноценного межпроцедурного анализа необходимы все файлы программы и зависимости.
Основным достоинством этого типа анализаторов является меньше количество "шума" за счет частичного моделирования выполнения программ и возможность обнаружения более сложных дефектов.
Процесс поиска уязвимостей в действии
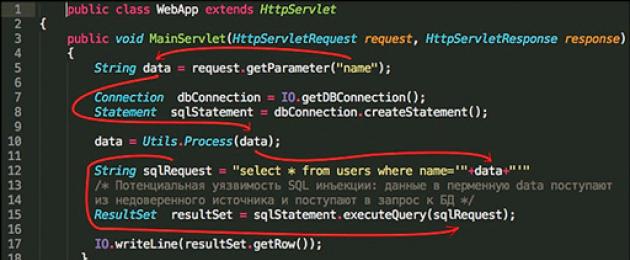
Для иллюстрации приведем процесс поиска уязвимостей инъекции кода и SQL-инъекции (рис. 1).

Для их обнаружения находятся места в программе, откуда поступают недоверенные данные (рис. 2), например, запрос протокола HTTP.

На листинге (рис. 1) 1 на строке 5 данные получаются из HTTP запроса, который поступает от пользователей при запросе Web-страницы. Например, при запросе страницы “http://example.com/main?name =‘ or 1=‘1”. Строка or 1=‘1 попадает в переменную data из объекта request, который содержит HTTP-запрос.
Дальше на строке 10 идет вызов функции Process с аргументом data, которая обрабатывает полученную строку. На строке 12 – конкатенация полученной строки data и запроса к базе данных, уже на строке 15 происходит вызов функции запроса к базе данных c результирующим запросом. В результате данных манипуляции получается запрос к базе данных вида: select * from users where name=‘’ or ‘1’=‘1’.
Что означает выбрать из таблицы всех пользователей, а не пользователя с определенным именем. Это не является стандартным функционалом и влечет нарушение конфиденциальности, что соответственно означает уязвимость. В результате потенциальный злоумышленник может получить информацию о всех пользователях, а не только о конкретном. Также он может получить данные из других таблиц, например содержащих пароли и другие критичные данные. А в некоторых случаях – исполнить свой вредоносный код.
Статические анализаторы работают похожим образом: помечают данные, которые поступают из недоверенного источника, отслеживаются все манипуляции с данными и пытаются определить, попадают ли данные в критичные функции. Под критичными функциями обычно подразумеваются функции, которые исполняют код, делают запросы к БД, обрабатывают XML-документы, осуществляют доступ к файлам и др., в которых изменение параметра функции может нанести ущерб конфиденциальности, целостности и доступности.
Также возможна обратная ситуация, когда из доверенного источника, например переменных окружения, критичных таблиц базы данных, критичных файлов, данные поступают в недоверенный источник, например генерируемую HTML-страницу. Это может означать потенциальную утечку критичной информации.
Одним из недостатков такого анализа является сложность определения на пути выполнения программ функций, которые осуществляют фильтрацию или валидацию значений. Поэтому большинство анализаторов включает набор стандартных системных функций фильтрации для языка и возможность задания таких функций самостоятельно.
Автоматизированный поиск уязвимостей
Достаточно сложно достоверно определить автоматизированными методами наличие закладок в ПО, поскольку необходимо понимать, какие функции выполняет определенный участок программы и являются ли они необходимыми программе, а не внедрены для обхода доступа к ресурсам системы. Но можно найти закладки по определенным признакам (рис. 3). Например, доступ к системе при помощи сравнения данных для авторизации или аутентификации с предопределенными значениями, а не использование стандартных механизмов авторизации или аутентификации. Найти данные признаки можно с помощью простого сигнатурного метода, но анализ потоков данных позволяет более точно определять предопределенные значения в программе, отслеживая, откуда поступило значение, динамически из базы данных или он было "зашито" в программе, что повышает точность анализа.

Нет общего мнения по поводу обязательного функционала третьего поколения инструментов статического анализа. Некоторые вендоры предлагают более тесную интеграцию в процесс разработки, использование SMT-решателей для точного определения пути выполнения программы в зависимости от данных.
Также есть тенденция добавления гибридного анализа, то есть совмещенных функций статического и динамического анализов. У данного подхода есть несомненные плюсы: например, можно проверять существование уязвимости, найденной с помощью статического анализа путем эксплуатации этой уязвимости. Недостатком такого подхода может быть следующая ситуация. В случае ошибочной корреляции места, где не было доказано уязвимостей с помощью динамического анализа, возможно появление ложноотрицательного результата. Другими словами, уязвимость есть, но анализатор ее не находит.
Если говорить о результатах анализа, то для оценки работы статического анализатора используется, как и в статистике, разделение результата анализа на положительный, отрицательный, ложноотрицатель-ный (дефект есть, но анализатор его не находит) и ложнопо-ложительный (дефекта нет, но анализатор его находит).
Для реализации эффективного процесса устранения дефектов важно отношение количества истинно найденных ко всем найденным дефектам. Данное отношение называют точностью. При небольшой точности получается большое соотношение истинных дефектов к ложноположительным, что так же, как и в ситуации с большим количеством шума, требует от разработчиков много времени на анализ результатов и фактически нивелирует плюсы автоматизированного анализа кода.
Для поиска уязвимостей особенно важно отношение найденных истинных уязвимостей ко всем найденным, поскольку данное отношение и принято считать полнотой. Ненайденные уязвимости опаснее ложнопо-ложительного результата, так как могут нести прямой ущерб бизнесу.
Достаточно сложно в одном решении сочетать хорошую полноту и точность анализа. Инструменты первого поколения, работающие по простому совпадению шаблонов, могут показывать хорошую полноту анализа, но при этом низкую точность из-за ограничения технологий. Благодаря тому что второе поколение анализаторов может определять зависимости и пути выполнения программы, обеспечивается более высокая точность анализа при такой же полноте.
Несмотря на то что развитие технологий происходит непрерывно, автоматизированные инструменты до сих пор не заменяют полностью ручной аудит кода. Такие категории дефектов, как логические, архитектурные уязвимости и проблемы с производительностью, могут быть обнаружены только экспертом. Однако инструменты работают быстрее, позволяют автоматизировать процесс и стоят дешевле, чем работа аудитора. При внедрении статического анализа кода можно использовать ручной аудит для первичной оценки, поскольку это позволяет обнаруживать серьезные проблемы с архитектурой. Автоматизированные же инструменты должны применяться для быстрого исправления дефектов. Например, при появлении новой версии ПО.
Существует множество решений для статического анализа исходного кода. Выбор продукта зависит от поставленных задач. Если необходимо повысить качество кода, то вполне можно использовать анализаторы первого поколения, использующие поиск по шаблонам. В случае когда нужно найти уязвимости в ходе реализации цикла безопасной разработки, логично использовать инструменты, использующие анализ потока данных. Ну а если опыт внедрения средств статического и динамического анализа уже имеется, можно попробовать средства, использующие гибридный анализ.
Колонка эксперта
Кибервойны: кибероружие
Петр
Ляпин
Начальник службы информационной безопасности, ООО “НИИ ТНН” (“Транснефть”)

Глядя на фактически развернутую гонку кибервооружений, прежде всего следует уяснить ряд фундаментальных положений в этой области.
Во-первых, война – международное явление, в котором участвуют два или более государства. Война подчиняется своим законам. Один из них гласит: "воюющие не пользуются неограниченным правом в выборе средств нанесения вреда неприятелю" 1 .
Во-вторых, давно канули в Лету те времена, когда вопросы войны и мира конфликтующие стороны могли решать самостоятельно. В условиях глобализации война становится делом всего международного сообщества. Более того, есть вполне действенный стабилизационный механизм – Совбез ООН. Однако в настоящий момент применять его к конфликтам в киберпространстве крайне затруднительно.
В-третьих, понятие кибервойны и кибероружия ни в одном действующем международном акте нет. Тем не менее следует разграничивать киберсредства, предназначенные для нанесения вреда (собственно кибероружие), и средства различного рода шпионажа. При этом термин "кибероружие" широко используется в том числе видными представителями научного сообщества.
Удачным видится определение кибероружия, данное профессором МГЮА В.А. Батырем: технические и программные средства поражения (устройства, программные коды), созданные государственными структурами, которые конструктивно предназначены для воздействия на программируемые системы, эксплуатацию уязвимостей в системах передачи и обработки информации или программно-технических системах с целью уничтожения людей, нейтрализации технических средств, либо разрушения объектов инфраструктуры противника 2 . Это определение во многом соответствует объективной действительности – не всякий "удачный вирус" есть кибероружие.
Так, к кибероружию можно отнести: Stuxnet и Flame, ботнеты, используемые для распределенных атак, массово внедряемые на этапе производства элементной базы аппаратные и программные закладки. Последнее, к слову, серьезнейшая проблема, масштаб которой невозможно переоценить. Достаточно взглянуть на перечень закладок АНБ США (от коммутаторов до USB-кабелей), опубликованный немецким СМИ Spiegel в декабре 2013 г. Смартфоны, ТВ, холодильники и прочая бытовая техника, подключенная к Интернету, вообще стирает всякие границы прогнозов.
___________________________________________
1 Дополнительный протокол I 1977 г. к Женевским конвенциям о защите жертв войны 1949 г.
2 Статья В.А. Батыря в Евразийском юридическом журнале (2014, №2) “Новые вызовы XXI в. в сфере развития средств вооруженной борьбы".
Термин обычно применяют к анализу, производимому специальным ПО, тогда как ручной анализ называют пониманием или постижением программы.
В зависимости от используемого инструмента глубина анализа может варьироваться от определения поведения отдельных операторов до анализа, включающего весь имеющийся исходный код. Способы использования полученной в ходе анализа информации также различны - от выявления мест, возможно содержащих ошибки, до формальных методов, позволяющих математически доказать какие-либо свойства программы (например, соответствие поведения спецификации).
Некоторые люди считают программные метрики и обратное проектирование формами статического анализа.
В последнее время статический анализ всё больше используется в верификации свойств ПО, используемого в компьютерных системах высокой надёжности.
Большинство компиляторов (например, GNU C Compiler) выводят на экран «предупреждения» (англ. warnings ) - сообщения о том, что код, будучи синтаксически правильным, скорее всего, содержит ошибку. Например:
Int x; int y = x+ 2 ; // Переменная x не инициализирована!
Это простейший статический анализ. У компилятора есть много других немаловажных характеристик - в первую очередь скорость работы и качество машинного кода, поэтому компиляторы проверяют код лишь на очевидные ошибки. Статические анализаторы предназначены для более детального исследования кода.
Типы ошибок, обнаруживаемых статическими анализаторами
- Неопределённое поведение - неинициализированные переменные, обращение к NULL-указателям. О простейших случаях сигнализируют и компиляторы.
- Нарушение блок-схемы пользования библиотекой. Например, для каждого fopen нужен fclose . И если файловая переменная теряется раньше, чем файл закрывается, анализатор может сообщить об ошибке.
- Типичные сценарии, приводящие к недокументированному поведению. Стандартная библиотека языка Си известна большим количеством неудачных технических решений. Некоторые функции, например, gets , в принципе небезопасны. sprintf и strcpy безопасны лишь при определённых условиях.
- Переполнение буфера - когда компьютерная программа записывает данные за пределами выделенного в памяти буфера.
Void doSomething(const char * x) { char s[ 40 ] ; sprintf (s, "[%s]" , x) ; // sprintf в локальный буфер, возможно переполнение .... }
- Типичные сценарии, мешающие кроссплатформенности .
Object * p = getObject() ; int pNum = reinterpret_cast < int > (p) ; // на x86-32 верно, на x64 часть указателя будет потеряна; нужен size_t
- Ошибки в повторяющемся коде. Многие программы исполняют несколько раз одно и то же с разными аргументами. Обычно повторяющиеся фрагменты не пишут с нуля, а размножают и исправляют.
Dest.x = src.x + dx; dest.y = src.y + dx; // Ошибка, надо dy!
Std:: wstring s; printf ("s is %s" , s) ;
- Неизменный параметр, передаваемый в функцию - признак изменившихся требований к программе. Когда-то параметр был задействован, но сейчас он уже не нужен. В таком случае программист может вообще избавиться от этого параметра - и от связанной с ним логики.
Void doSomething(int n, bool flag) // flag всегда равен true { if (flag) { // какая-то логика } else { // код есть, но не задействован } } doSomething(n, true ) ; ... doSomething (10 , true ) ; ... doSomething (x.size () , true ) ;
Std:: string s; ... s .empty () ; // код ничего не делает; вероятно, вы хотели s.clear()?
Формальные методы
Инструменты статического анализа
- Coverity
- lint и lock_lint, входящие в состав Sun Studio
- T-SQL Analyzer - инструмент, который может просматривать программные модули в базах данных под управлением Microsoft SQL Server 2005 или 2008 и обнаруживать потенциальные проблемы, связанные с низким качеством кода.
- АК-ВС
См. также
- Формальная семантика ЯП
- Анализ программного обеспечения
- Постепенная деградация
- SPARK - ЯП
Примечания
Ссылки
Wikimedia Foundation . 2010 .
Смотреть что такое "Статический анализ кода" в других словарях:
- (англ. Dynamic program analysis) анализ программного обеспечения, выполняемый при помощи выполнения программ на реальном или виртуальном процессоре (анализ, выполняемый без запуска программ называется статический анализ кода). Утилиты… … Википедия
Анализ потока управления это статический анализ кода для определения порядка выполнения программы. Порядок выполнения выражается в виде графа потока управления. Для многих языков граф потока управления явно прослеживается в исходном коде… … Википедия
У этого термина существуют и другие значения, см. BLAST (значения). BLAST Тип Инструменты статического анализа Разработчик Dirk Beyer, Thomas Henzinger, Ranjit Jhala, Rupak Majumdar, Berkeley Операционная система Linux, Microsoft Windows… … Википедия
В следующие таблицы включены пакеты программ, которые являются интегрированными средствами разработки. Отдельные компиляторы и отладчики не упомянуты. Возможно, в английском разделе есть более свежая информация. Содержание 1 ActionScript 2 Ада 3 … Википедия
Отладка этап разработки компьютерной программы, на котором обнаруживают, локализуют и устраняют ошибки. Чтобы понять, где возникла ошибка, приходится: узнавать текущие значения переменных; выяснять, по какому пути выполнялась… … Википедия
Тип Статический анализатор кода Разработчик лаборатория BiPro Написана на С++ Операционная система Кроссплатформенное Языки интерфейса английский … Википедия
При написании кода на C и C++ люди допускают ошибки. Многие из этих ошибок находятся благодаря -Wall , ассертам, тестам, дотошному code review, предупреждениям со стороны IDE, сборкой проекта разными компиляторами под разные ОС, работающие на разном железе, и так далее. Но даже при использовании всех этих мер ошибки часто остаются незамеченными. Немного улучшить положение дел позволяет статический анализ кода. В этой заметке мы познакомимся с некоторыми инструментами для произведения этого самого статического анализа.
CppCheck
CppCheck является бесплатным кроссплатформенным статическим анализатором с открытым исходным кодом (GPLv3). Он доступен в пакетах многих *nix систем из коробки. Также CppCheck умеет интегрироваться со многими IDE. На момент написания этих строк CppCheck является живым, развивающимся проектом.
Пример использования:
cppcheck ./ src/
Пример вывода:
: (error) Common realloc mistake: "numarr" nulled but not
freed upon failure
: (error) Dangerous usage of "n" (strncpy doesn"t always
null-terminate it)
CppCheck хорош тем, что он довольно быстро работает. Нет повода не добавить его прогон в систему непрерывной интеграции , чтобы исправлять прямо все-все-все выводимые им предупреждения. Даже несмотря на то, что многие из них на практике оказываются ложно-положительными срабатываниями.
Clang Static Analyzer
Еще один бесплатный кроссплатформенный статический анализатор с открытыми исходным кодом. Является частью так называемого LLVM-стэка . В отличие от CppCheck работает существенно медленнее, но и ошибки находит куда более серьезные.
Пример построения отчета для PostgreSQL :
CC
=/
usr/
local/
bin/
clang38 CFLAGS
="-O0 -g"
\
./
configure --enable-cassert
--enable-debug
gmake
clean
mkdir
../
report-201604
/
/
usr/
local/
bin/
scan-build38 -o
../
report-201604
/
gmake
-j2
Пример построения отчета для ядра FreeBSD :
# использование своего MAKEOBJDIR позволяет собирать ядро не под рутом
mkdir
/
tmp/
freebsd-obj
# сама сборка
COMPILER_TYPE
=clang /
usr/
local/
bin/
scan-build38 -o
../
report-201604
/
\
make
buildkernel KERNCONF
=GENERIC MAKEOBJDIRPREFIX
=/
tmp/
freebsd-obj
Идея, как несложно догадаться, заключается в том, чтобы сделать clean, а затем запустить сборку под scan-build.
На выходе получается очень симпатичный HTML-отчет с подробнейшими пояснениями, возможностью фильтровать ошибки по их типу, и так далее. Обязательно посмотрите на офсайте как это примерно выглядит.
В данном контексте не могу не отметить, что в мире Clang/LLVM есть еще и средства динамического анализа, так называемые «санитайзеры». Их много, они находят очень крутые ошибки и работают быстрее, чем Valgrind (правда, только под Linux). К сожалению, обсуждение санитайзеров выходит за рамки настоящей заметки, поэтому ознакомьтесь с ними самостоятельно .
PVS-Studio
Закрытый статический анализатор, распространяемый за деньги. PVS-Studio работает только под Windows и только с Visual Studio. Есть многочисленные сведения о существовании Linux-версии, но на официальном сайте она не доступна. Насколько я понял, цена лицензии обсуждается индивидуально с каждым клиентом. Доступен триал.
Я протестировал PVS-Studio 6.02 на Windows 7 SP1 работающей под KVM с установленной Visual Studio 2013 Express Edition. Во время установки PVS-Studio также дополнительно скачался.NET Framework 4.6. Выглядит это примерно так. Вы открываете проект (я тестировал на PostgreSQL) в Visual Studio, в PVS-Studio жмете «сейчас я начну собирать проект», затем в Visual Studio нажимаете Build, по окончании сборки в PVS-Studio жмете «я закончил» и смотрите отчет.
PVS-Studio действительно находит очень крутые ошибки, которые Clang Static Analyzer не видит (например). Также очень понравился интерфейс, позволяющий сортировать и фильтровать ошибки по их типу, серьезности, файлу, в котором они были найдены, и так далее.
С одной стороны, печалит, что чтобы использовать PVS-Studio, проект должен уметь собираться под Windows. С другой стороны, использовать в проекте CMake и собирать-тестировать его под разными ОС, включая Windows, при любом раскладе является очень неплохой затеей. Так что, пожалуй, это не такой уж и большой недостаток. Кроме того, по следующим ссылкам можно найти кое-какие подсказки касательно того, как людям удавалось прогонять PVS-Studio на проектах, которые не собираются под Windows: раз , два , три , четыре .
Дополнение: Попробовал бета-версию PVS-Studio для Linux. Пользоваться ею оказалось очень просто . Создаем pvs.conf примерно такого содержания:
lic-file=/home/afiskon/PVS-Studio.lic
output-file=/home/afiskon/postgresql/pvs-output.log
Затем говорим:
make
clean
./
configure ...
pvs-studio-analyzer trace --
make
# будет создан большой (у меня ~40 Мб) файл strace_out
pvs-studio-analyzer analyze --cfg
./
pvs.conf
plog-converter -t
tasklist -o
result.task pvs-output.log
Дополнение: PVS-Studio для Linux вышел из беты и теперь доступен всем желающим .
Coverity Scan
Coverity считается одним из самых навороченных (а следовательно и дорогих) статических анализаторов. К сожалению, на официальном сайте невозможно скачать даже его триал-версию. Можно заполнить форму, и если вы какой-нибудь IBM, с вами может быть свяжутся. При очень сильном желании Coverity какой-нибудь доисторической версии можно найти через неофициальные каналы. Он бывает для Windows и Linux, работает примерно по тому же принципу, что и PVS-Studio. Но без серийника или лекарства отчеты Coverity вам не покажет. А чтобы найти серийник или лекарство, нужно иметь не просто очень сильное желание, а очень-очень-очень сильное.
К счастью, у Coverity есть SaaS версия — Coverity Scan. Мало того, что Coverity Scan доступен для простых смертных, он еще и совершенно бесплатен. Привязки к конкретной платформе нет. Однако анализировать с помощью Coverity Scan разрешается только открытые проекты.
Вот как это работает. Вы регистрируете свой проект через веб-интерфейс (или присоединяетесь к уже существующему, но это менее интересный кейс). Чтобы посмотреть отчеты, нужно пройти модерацию, которая занимает 1-2 рабочих дня.
Отчеты строятся таким образом. Сначала вы локально собираете свой проект под специальной утилитой Coverity Build Tool. Утилита эта аналогична scan-build из Clang Static Analyzer и доступна под все мыслимые платформы, включая всякую экзотику типа FreeBSD или даже NetBSD.
Установка Coverity Build Tool:
tar
-xvzf
cov-analysis-linux64-7.7.0.4.tar.gz
export
PATH
=/
home/
eax/
temp/
cov-analysis-linux64-7.7.0.4/
bin:$PATH
Готовим тестовый проект (я использовал код из заметки Продолжаем изучение OpenGL: простой вывод текста):
git clone
git
@
github.com:afiskon/
c-opengl-text.git
cd
c-opengl-text
git submodule
init
git submodule
update
mkdir
build
cd
build
cmake
..
Затем собираем проект под cov-build:
cov-build --dir cov-int make -j2 demo emdconv
Важно! Не меняйте название директории cov-int.
Архивируем директорию cov-int:
tar -cvzf c-opengl-text.tgz cov-int
Заливаем архив через форму Upload a Project Build. Также на сайте Coverity Scan есть инструкции по автоматизации этого шага при помощи curl. Ждем немного, и можно смотреть результаты анализа. Примите во внимание, что чтобы пройти модерацию, нужно отправить на анализ хотя бы один билд.
Ошибки Coverity Scan ищет очень хорошо. Уж точно лучше, чем Clang Static Analyzer. При этом ложно-положительные срабатывания есть, но их намного меньше. Что удобно, в веб-интерфейсе есть что-то вроде встроенного багтрекера, позволяющего присваивать ошибкам серьезность, ответственного за их исправление и подобные вещи. Видно, какие ошибки новые, а какие уже были в предыдущих билдах. Ложно-положительные срабатывания можно отметить как таковые и скрыть.
Заметьте, что чтобы проанализировать проект в Coverity Scan, не обязательно быть его владельцем. Мне лично вполне успешно удалось проанализировать код PostgreSQL без присоединения к уже существующему проекту. Думается также, что при сильном желании (например, используя сабмодули Git), можно подсунуть на проверку немного и не очень-то открытого кода.
Заключение
Вот еще несколько статических анализаторов, не попавших в обзор:
Каждый из рассмотренных анализаторов находят такие ошибки, которые не находят другие. Поэтому в идеале лучше использовать их сразу все. Делать это вот прямо постоянно, скорее всего, объективно не получится. Но делать хотя бы один прогон перед каждым релизом точно будет не лишним. При этом Clang Static Analyzer выглядит наиболее универсальным и при этом достаточно мощным. Если вас интересует один анализатор, который нужно обязательно использовать в любом проекте, используйте его. Но все же я бы рекомендовал дополнительно использовать как минимум PVS-Studio или Coverity Scan.
А какие статические анализаторы вы пробовали и/или регулярно использовали и каковы ваши впечатления от них?
Аннотация
В настоящее время разработано большое количество инструментальных средств, предназначенных для автоматизации поиска уязвимостей программ. В данной статье будут рассмотрены некоторые из них.
Введение
Статический анализ кода - это анализ программного обеспечения, который производится над исходным кодом программ и реализуется без реального исполнения исследуемой программы.
Программное обеспечение часто содержит разнообразные уязвимости из-за ошибок в коде программ. Ошибки, допущенные при разработке программ, в некоторых ситуациях приводят к сбою программы, а следовательно, нарушается нормальная работа программы: при этом часто возникает изменение и порча данных, останов программы или даже системы. Большинство уязвимостей связано с неправильной обработкой данных, получаемых извне, или недостаточно строгой их проверкой.
Для выявления уязвимостей используют различные инструментальные средства, например, статические анализаторы исходного кода программы, обзор которых приведён в данной статье.
Классификация уязвимостей защиты
Когда требование корректной работы программы на всех возможных входных данных нарушается, становится возможным появление так называемых уязвимостей защиты (security vulnerability). Уязвимости защиты могут приводить к тому, что одна программа может использоваться для преодоления ограничений защиты всей системы в целом.
Классификация уязвимостей защиты в зависимости от программных ошибок:
- Переполнение буфера (buffer overflow). Эта уязвимость возникает из-за отсутствия контроля за выходом за пределы массива в памяти во время выполнения программы. Когда слишком большой пакет данных переполняет буфер ограниченного размера, содержимое посторонних ячеек памяти перезаписывается, и происходит сбой и аварийный выход из программы. По месту расположения буфера в памяти процесса различают переполнения буфера в стеке (stack buffer overflow), куче (heap buffer overflow) и области статических данных (bss buffer overflow).
- Уязвимости (tainted input vulnerability). Уязвимости могут возникать в случаях, когда вводимые пользователем данные без достаточного контроля передаются интерпретатору некоторого внешнего языка (обычно это язык Unix shell или SQL). В этом случае пользователь может таким образом задать входные данные, что запущенный интерпретатор выполнит совсем не ту команду, которая предполагалась авторами уязвимой программы.
- Ошибки форматных строк (format string vulnerability). Данный тип уязвимостей защиты является подклассом уязвимости. Он возникает из-за недостаточного контроля параметров при использовании функций форматного ввода-вывода printf, fprintf, scanf, и т. д. стандартной библиотеки языка Си. Эти функции принимают в качестве одного из параметров символьную строку, задающую формат ввода или вывода последующих аргументов функции. Если пользователь сам может задать вид форматирования, то эта уязвимость может возникнуть в результате неудачного применения функций форматирования строк.
- Уязвимости как следствие ошибок синхронизации (race conditions). Проблемы, связанные с многозадачностью, приводят к ситуациям, называемым: программа, не рассчитанная на выполнение в многозадачной среде, может считать, что, например, используемые ею при работе файлы не может изменить другая программа. Как следствие, злоумышленник, вовремя подменяющий содержимое этих рабочих файлов, может навязать программе выполнение определенных действий.
Конечно, кроме перечисленных существуют и другие классы уязвимостей защиты.
Обзор существующих анализаторов
Для обнаружения уязвимостей защиты в программах применяют следующие инструментальные средства:
- Динамические отладчики. Инструменты, которые позволяют производить отладку программы в процессе её исполнения.
- Статические анализаторы (статические отладчики). Инструменты, которые используют информацию, накопленную в ходе статического анализа программы.
Статические анализаторы указывают на те места в программе, в которых возможно находится ошибка. Эти подозрительные фрагменты кода могут, как содержать ошибку, так и оказаться совершенно безопасными.
В данной статье предложен обзор нескольких существующих статических анализаторов. Рассмотрим подробнее каждый из них.
1. BOON
Инструмент , который на основе глубокого семантического анализа автоматизирует процесс сканирования исходных текстов на Си в поисках уязвимых мест, способных приводить к переполнению буфера. Он выявляет возможные дефекты, предполагая, что некоторые значения являются частью неявного типа с конкретным размером буфера.
2. CQual
Инструмент анализа для обнаружения ошибок в Си-программах. Программа расширяет язык Си дополнительными определяемыми пользователем спецификаторами типа. Программист комментирует свою программу с соответствующими спецификаторами, и cqual проверяет ошибки. Неправильные аннотации указывают на потенциальные ошибки. Сqual может использоваться, чтобы обнаружить потенциальную уязвимость форматной строки.
3. MOPS
(MOdel checking Programs for Security) - инструмент для поиска уязвимостей в защите в программах на Си. Его назначение: динамическая корректировка, обеспечивающая соответствие программы на Си статической модели. MOPS использует модель аудита программного обеспечения, которая призвана помочь выяснить, соответствует ли программа набору правил, определенному для создания безопасных программ.
4. ITS4, RATS, PScan, Flawfinder
Для поиска ошибок переполнения буфера и ошибок форматных строк используют следующие статические анализаторы:
- . Простой инструмент, который статически просматривает исходный Си/Си++-код для обнаружения потенциальных уязвимостей защиты. Он отмечает вызовы потенциально опасных функций, таких, например, как strcpy/memcpy, и выполняет поверхностный семантический анализ, пытаясь оценить, насколько опасен такой код, а так же дает советы по его улучшению.
- . Утилита RATS (Rough Auditing Tool for Security) обрабатывает код, написанный на Си/Си++, а также может обработать еще и скрипты на Perl, PHP и Python. RATS просматривает исходный текст, находя потенциально опасные обращения к функциям. Цель этого инструмента - не окончательно найти ошибки, а обеспечить обоснованные выводы, опираясь на которые специалист сможет вручную выполнять проверку кода. RATS использует сочетание проверок надежности защиты от семантических проверок в ITS4 до глубокого семантического анализа в поисках дефектов, способных привести к переполнению буфера, полученных из MOPS.
- . Сканирует исходные тексты на Си в поисках потенциально некорректного использования функций, аналогичных printf, и выявляет уязвимые места в строках формата.
- . Как и RATS, это статический сканер исходных текстов программ, написанных на Си/Си++. Выполняет поиск функций, которые чаще всего используются некорректно, присваивает им коэффициенты риска (опираясь на такую информацию, как передаваемые параметры) и составляет список потенциально уязвимых мест, упорядочивая их по степени риска.
Все эти инструменты схожи и используют только лексический и простейший синтаксический анализ. Поэтому результаты, выданные этими программами, могут содержать до 100% ложных сообщений.
5. Bunch
Средство анализа и визуализации программ на Си, которое строит граф зависимостей, помогающий аудитору разобраться в модульной структуре программы.
6. UNO
Простой анализатор исходного кода. Он был разработан для нахождения таких ошибок, как неинициализированные переменные, нулевые указатели и выход за пределы массива. UNO позволяет выполнять несложный анализ потока управления и потоков данных, осуществлять как внутри- так и межпроцедурный анализ, специфицировать свойства пользователя. Но данный инструмент не доработан для анализа реальных приложений, не поддерживает многие стандартные библиотеки и на данном этапе разработки не позволяет анализировать сколь-нибудь серьёзные программы.
7. FlexeLint (PC-Lint)
Этот анализатор предназначен для анализа исходного кода с целью выявления ошибок различного типа. Программа производит семантический анализ исходного кода, анализ потоков данных и управления.
В конце работы выдаются сообщения нескольких основных типов:
- Возможен нулевой указатель;
- Проблемы с выделением памяти (например, нет free() после malloc());
- Проблемный поток управления (например, недостижимый код);
- Возможно переполнение буфера, арифметическое переполнение;
- Предупреждения о плохом и потенциально опасном стиле кода.
8. Viva64
Инструмент , который помогает специалисту отслеживать в исходном коде Си/Си++-программ потенциально опасные фрагменты, связанные с переходом от 32-битных систем к 64-битным. Viva64 встраивается в среду Microsoft Visual Studio 2005/2008, что способствует удобной работе с этим инструментом. Анализатор помогает писать корректный и оптимизированный код для 64-битных систем.
9. Parasoft C++ Test
Специализированный инструмент для Windows, позволяющий автоматизировать анализ качества кода Си++. Пакет C++Test анализирует проект и генерирует код, предназначенный для проверки содержащихся в проекте компонентов. Пакет C++Test делает очень важную работу по анализу классов C++. После того как проект загружен, необходимо настроить методы тестирования. Программное обеспечение изучает каждый аргумент метода и возвращает типы соответствующих значений. Для данных простых типов подставляются значения аргументов по умолчанию; можно определить тестовые данные для определенных пользователем типов и классов. Можно переопределить аргументы C++Test, используемые по умолчанию, и выдать значения, полученные в результате тестирования. Особого внимания заслуживает способность C++Test тестировать незавершенный код. Программное обеспечение генерирует код-заглушку для любого метода и функции, которые еще не существуют. Поддерживается имитация внешних устройств и входных данных, задаваемых пользователем. И та и другая функции допускают возможность повторного тестирования. После определения тестовых параметров для всех методов пакет C++Test готов к запуску исполняемого кода. Пакет генерирует тестовый код, вызывая для его подготовки компилятор Visual C++. Возможно формирование тестов на уровне метода, класса, файла и проекта.
10. Coverity
Инструменты используются для выявления и исправления дефектов безопасности и качества в приложениях критического назначения. Технология компании Coverity устраняет барьеры в написании и внедрении сложного ПО посредством автоматизации поиска и устранения критических программных ошибок и недостатков безопасности во время процесса разработки. Инструмент компании Coverity способен с минимальной положительной погрешностью обрабатывать десятки миллионов строк кода, обеспечивая 100-процентное покрытие трассы.
11. KlocWork K7
Продукты компании предназначены для автоматизированного статического анализа кода, выявления и предотвращения дефектов программного обеспечения и проблем безопасности. Инструменты этой компании служат для выявления коренных причин недостатков качества и безопасности программного обеспечения, для отслеживания и предотвращения этих недостатков на протяжении всего процесса разработки.
12. Frama-C
Открытый, интегрированный набор инструментов для анализа исходного кода на языке Си. Набор включает ACSL (ANSI/ISO C Specification Language) - специальный язык, позволяющий подробно описывать спецификации функций Си, например, указать диапазон допустимых входных значений функции и диапазон нормальных выходных значений.
Этот инструментарий помогает производить такие действия:
- Осуществлять формальную проверку кода;
- Искать потенциальные ошибки исполнения;
- Произвести аудит или рецензирование кода;
- Проводить реверс-инжиниринг кода для улучшения понимания структуры;
- Генерировать формальную документацию.
13. CodeSurfer
Инструмент анализа программ, который не предназначается непосредственно для поиска ошибок уязвимости защиты. Его основными достоинствами являются:
- Анализ указателей;
- Различные анализы потока данных (использование и определение переменных, зависимость данных, построение графа вызовов);
- Скриптовый язык.
CodeSurfer может быть использован для поиска ошибок в исходном коде, для улучшения понимания исходного кода, и для реинженерии программ. В рамках среды CodeSurfer велась разработка прототипа инструментального средства для обнаружения уязвимостей защиты, однако разработанное инструментальное средство используется только внутри организации разработчиков.
14. FxCop
Предоставляет средства автоматической проверки.NET-сборок на предмет соответствия правилам Microsoft .NET Framework Design Guidelines. Откомпилированный код проверяется с помощью механизмов рефлексии, парсинга MSIL и анализа графа вызовов. В результате FxCop способен обнаружить более 200 недочетов (или ошибок) в следующих областях:
- Архитектура библиотеки;
- Локализация;
- Правила именования;
- Производительность;
- Безопасность.
FxCop предусматривает возможность создания собственных правил с помощью специального SDK. FxCop может работать как в графическом интерфейсе, так и в командной строке.
15. JavaChecker
Это статический анализатор Java програм, основанный на технологии TermWare.
Это средство позволяет выявлять дефекты кода, такие как:
- небрежная обработка исключений (пустые catch-блоки, генерирование исключений общего вида и.т.п.);
- сокрытие имен (например, когда имя члена класса совпадает с именем формального параметра метода);
- нарушения стиля (вы можете задавать стиль программирования с помощью набора регулярных выражений);
- нарушения стандартных контрактов использования (например, когда переопределен метод equals, но не hashCode);
- нарушения синхронизации (например, когда доступ к синхронизированной переменной находится вне synchronized блока).
Набором проверок можно управлять, используя управляющие комментарии.
Вызов JavaChecker можно осуществлять из ANT скрипта.
16. Simian
Анализатор подобия, который ищет повторяющийся синтаксис в нескольких файлах одновременно. Программа понимает синтаксис различных языков программирования, включая C#, T-SQL, JavaScript и Visual BasicR, а также может искать повторяющиеся фрагменты в текстовых файлах. Множество возможностей настройки позволяет точно настраивать правила поиска дублирующегося кода. Например, параметр порога (threshold) определяет, какое количество повторяющихся строк кода считать дубликатом.
Simian - это небольшой инструмент, разработанный для эффективного поиска повторений кода. У него отсутствует графический интерфейс, но его можно запустить из командной строки или обратиться к нему программно. Результаты выводятся в текстовом виде и могут быть представлены в одном из встроенных форматов (например, XML). Хотя скудный интерфейс и ограниченные возможности вывода результатов Simian требуют некоторого обучения, он помогает сохранить целостность и эффективность продукта. Simian подходит для поиска повторяющегося кода как в больших, так и в маленьких проектах.
Повторяющийся код снижает поддерживаемость и обновляемость проекта. Можно использовать Simian для быстрого поиска дублирующихся фрагментов кода во многих файлах одновременно. Поскольку Simian может быть запущен из командной строки, его можно включить в процесс сборки, чтобы получить предупреждения или остановить процесс в случае повторений кода.
Вывод
Итак, в данной статье были рассмотрены статические анализаторы исходного кода, которые являются вспомогательными инструментами программиста. Все инструментальные средства разные и помогают отслеживать самые различные классы уязвимостей защиты в программах. Можно сделать вывод, что статические анализаторы должны быть точными, восприимчивыми. Но, к сожалению, статические средства отладки не могут дать абсолютно надёжный результат.